Dynamically deploy org-specific metadata with sfdx string replacements (must have for CI/CD!)
I'm really excited about this new awesome sfdx feature called String replacements! It finally provides a solution to deploying org-specific metadata in a scaleable way.
While the documentation is great, it does assume some advanced knowledge of shell scripts and bash, and it doesn't have good examples of how to get this to work in a CI/CD pipeline.
So, I bang my head against the screen for a few days so that you don't have to! After reading this article, you'll have all the knowledge required to implement dynamic metadata deployments.
Let's get started...
The problem
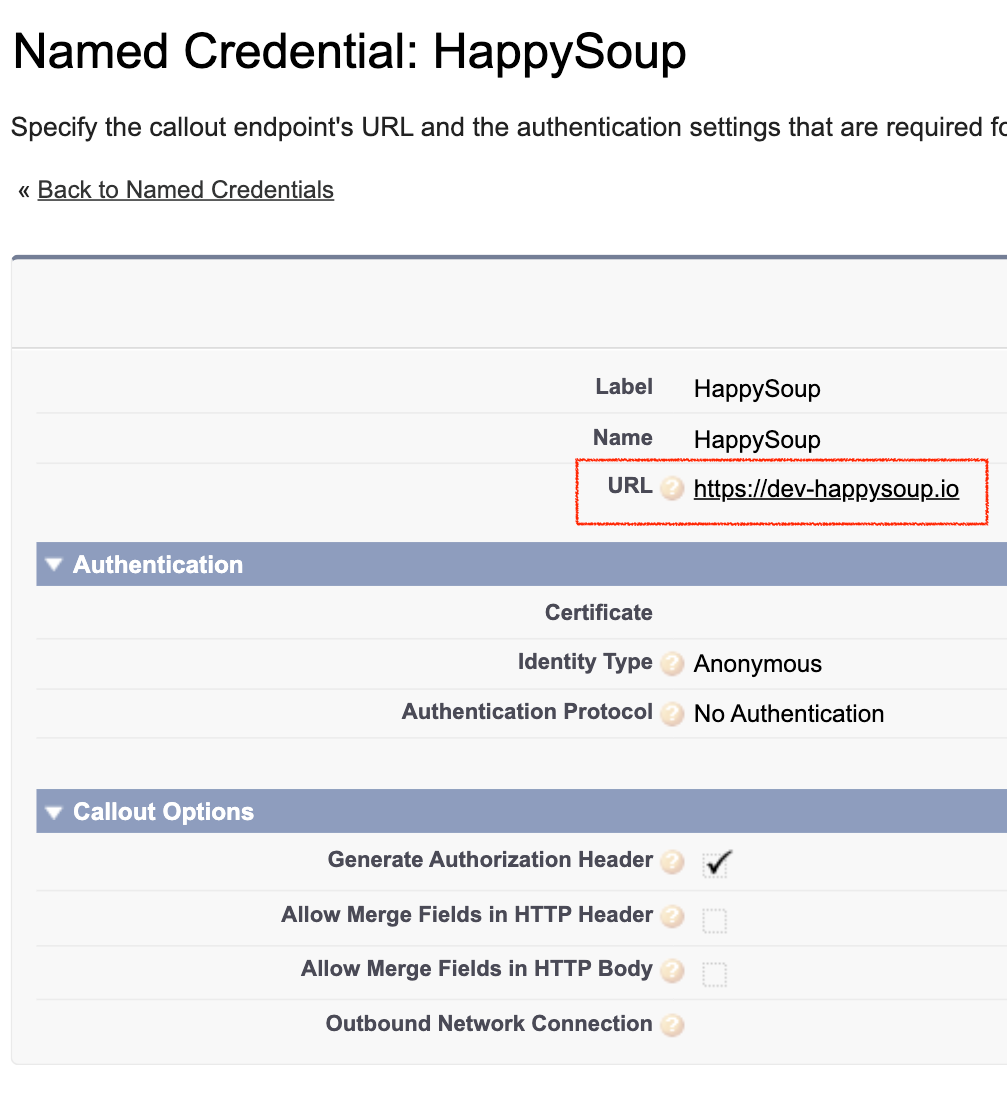
Let's say your Salesforce org has an integration with https://happysoup.io/. The authentication to HappySoup is stored in a named credential, which has points to HappySoup's production endpoint
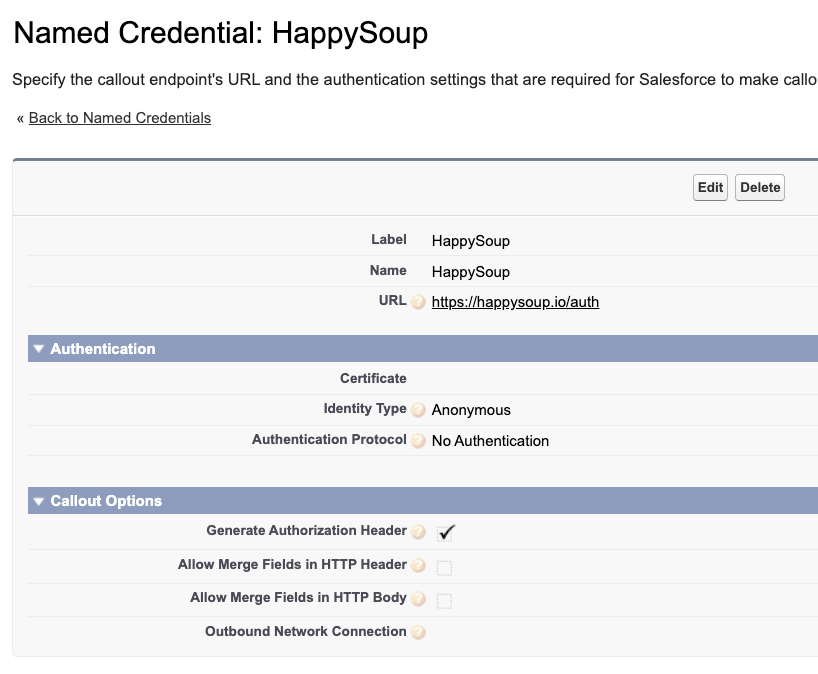
I'm managing this named credential in version control, so I've included it in my sfdx project:

<?xml version="1.0" encoding="UTF-8"?>
<NamedCredential xmlns="http://soap.sforce.com/2006/04/metadata">
<allowMergeFieldsInBody>false</allowMergeFieldsInBody>
<allowMergeFieldsInHeader>false</allowMergeFieldsInHeader>
<endpoint>https://happysoup.io/auth</endpoint>
<generateAuthorizationHeader>true</generateAuthorizationHeader>
<label>HappySoup</label>
<principalType>Anonymous</principalType>
<protocol>NoAuthentication</protocol>
</NamedCredential>In the snippet above, we can see the endpoint is hardcoded
<endpoint>https://happysoup.io/auth</endpoint>
Since our Git repository is supposed to contain the source of truth, we want to store the production value there.
The problem with this is every time the UAT sandbox is refreshed or every time this metadata is deployed to UAT, the endpoint should actually point to HappySoup's staging server https://uat-happysoup.io/auth
Historically, people have solved this problem in 2 ways:
1) Edit the metadata as a post-deployment step
Deploy the metadata as is based on the contents of your Git repo, and later log in to the org to manually change the metadata.
2) Store org-specific metadata in a separate folder of your sfdx project.
You could create separate folders for each org and store the org-specific metadata in said folders. For example:

Then, you could have some logic in your Continous Integration (CI) server to deploy a specific folder depending on which workflow is being executed.
For example, in GitHub actions, I could set a deploy-to-prod workflow that specifically deploys that folder
- name: Deployment
run: >
sfdx force:source:deploy -p "force-app/main/default/orgs/prod" --testlevel RunLocalTests --jsonI could then have another workflow called deploy-to-uat that deploys the folder force-app/main/default/orgs/uat
Obviously, this means I have two versions of the XML of the named credential. One with the production endpoint and another one with the staging endpoint.
This is not ideal because now I have 2 "sources of truth" for a given file.
What is needed is a way for the sfdx force:source:deploy command to "know" which org we are deploying to so that it can determine which endpoint to use in the named credential.
The new string replacements feature offers a much better way to handle this scenario by allowing us to dynamically replace the endpoint at deployment time.
Let's see how.
String replacements in action
With string replacements, I can create an entry in my sfdx-project.json file that looks like this
"replacements": [
{
"filename": "force-app/main/default/namedCredentials/HappySoup.namedCredential-meta.xml",
"stringToReplace": "https://happysoup.io/auth",
"replaceWithEnv": "HAPPY_SOUP_URL"
}
]Let's break this down. I'm basically saying
1) When the file ../namedCredentials/HappySoup.namedCredential-meta.xml is deployed with the Salesforce CLI
2) Check if the string https://happysoup.io/auth exists in it
3) If so, replace it with the value of the environment variable HAPPY_SOUP_URL
The environment variable is that, a variable. Meaning its value isn't hardcoded; instead, it depends on the environment where the command is executed.
I realize this may not make sense if you are not familiar with environment variables, so let's talk about that for a bit, then we'll come back to this.
What is an environment variable?
First of all, let's define what an environment is.
In this context, it may be easy to confuse an environment with a Salesforce org; after all, that's what we are talking about here: a way to deploy metadata in a way that it's aware of the target org.
However, an environment here refers to a shell environment or an execution environment. Programs that run in a terminal, like the Salesforce CLI, are executed within a shell.
Environment variables are variables that are available to programs that run on the shell during a specific shell session. Think of them like global variables in a program; they define high-level settings that can change how a program behaves at run time.
And like normal variables, they have a name and a value, like:
HAPPY_SOUP_URL=https://happysoup.io/auth
Let's see how I can create one in a terminal window of VS Code

Here, I used the export command to create an environment variable.
I can then access this variable using the $ character and the name of the variable, for example:

You can see that the value $HAPPY_SOUP_URL got replaced with the URL I set earlier with the export command.
This is not different than doing this in apex:
public with sharing class SampleClass {
public SampleClass() {
String url = 'happysoup.io';
System.debug('The URL is '+url);
}
}But here's where it gets interesting. In VS Code, I can open a new terminal window
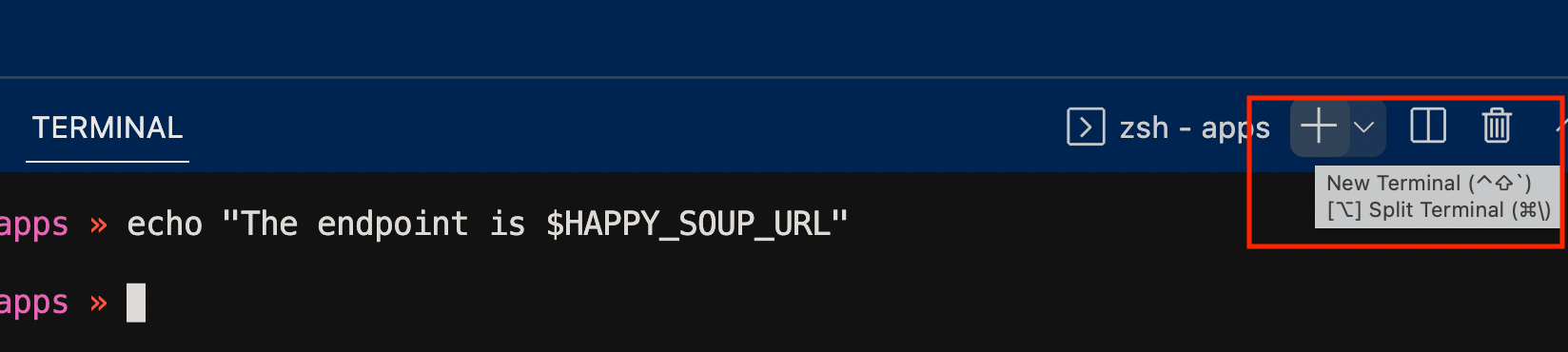
And if I run the same command in this new terminal, the variable is not resolved

Why not? Because it's not the same execution environment. The variable doesn't exist in this new shell environment.
Environment variables in software development
Now we know what an environment variable is and how it lives within a particular execution environment. But what's the point of them?
In traditional software development, environment variables are used to avoid hardcoding values.
This is no different than how we use custom settings or custom metadata types to avoid hardcoding values in apex. It's the same concept.
Let's see a real example.
In https://happysoup.io/, I use a Redis database to manage the session information of the logged-in user.
When I run HappySoup locally on my computer, the database is a program installed on my machine, and I connect to it by specifying its URL, port number, etc.
But the "real" HappySoup, the one at https://happysoup.io/, doesn't run on my computer; it runs on Heroku, so the URL of the database in Heroku is not the same as the one on my computer.
To get around this problem, I use environment variables in my code:
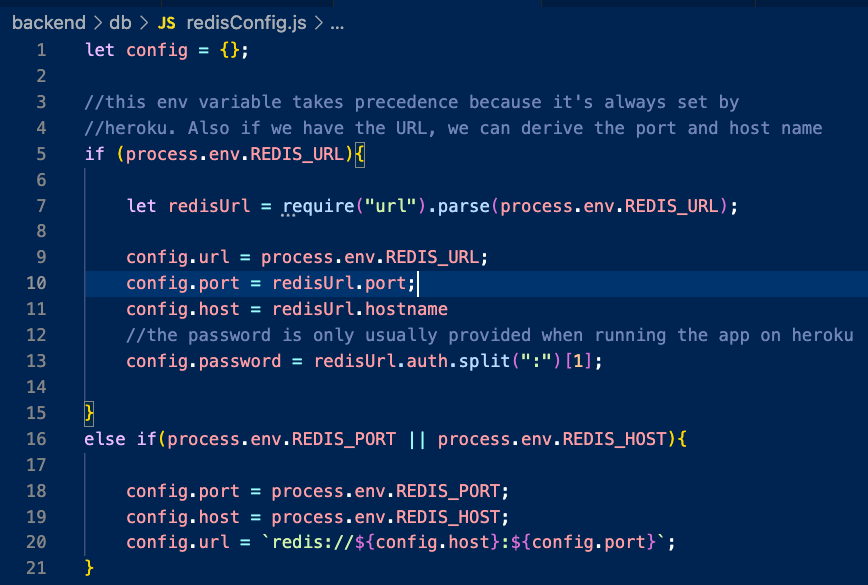
You'll see a lot of process.env.[name] strings. This is how I tell my code to look at the shell environment in which the NodeJs process is running to resolve those variables.
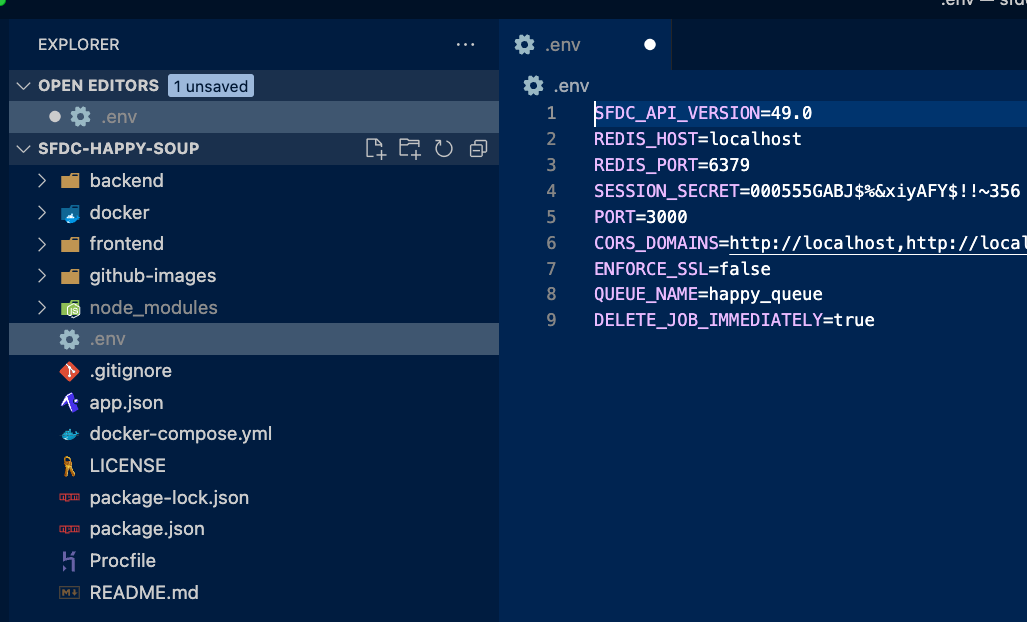
When I run HappySoup locally, I use a dot.env file to tell NodeJs how to resolve the environment variables
When HappySoup runs on Heroku, I specify the values of the variables via the Heroku UI
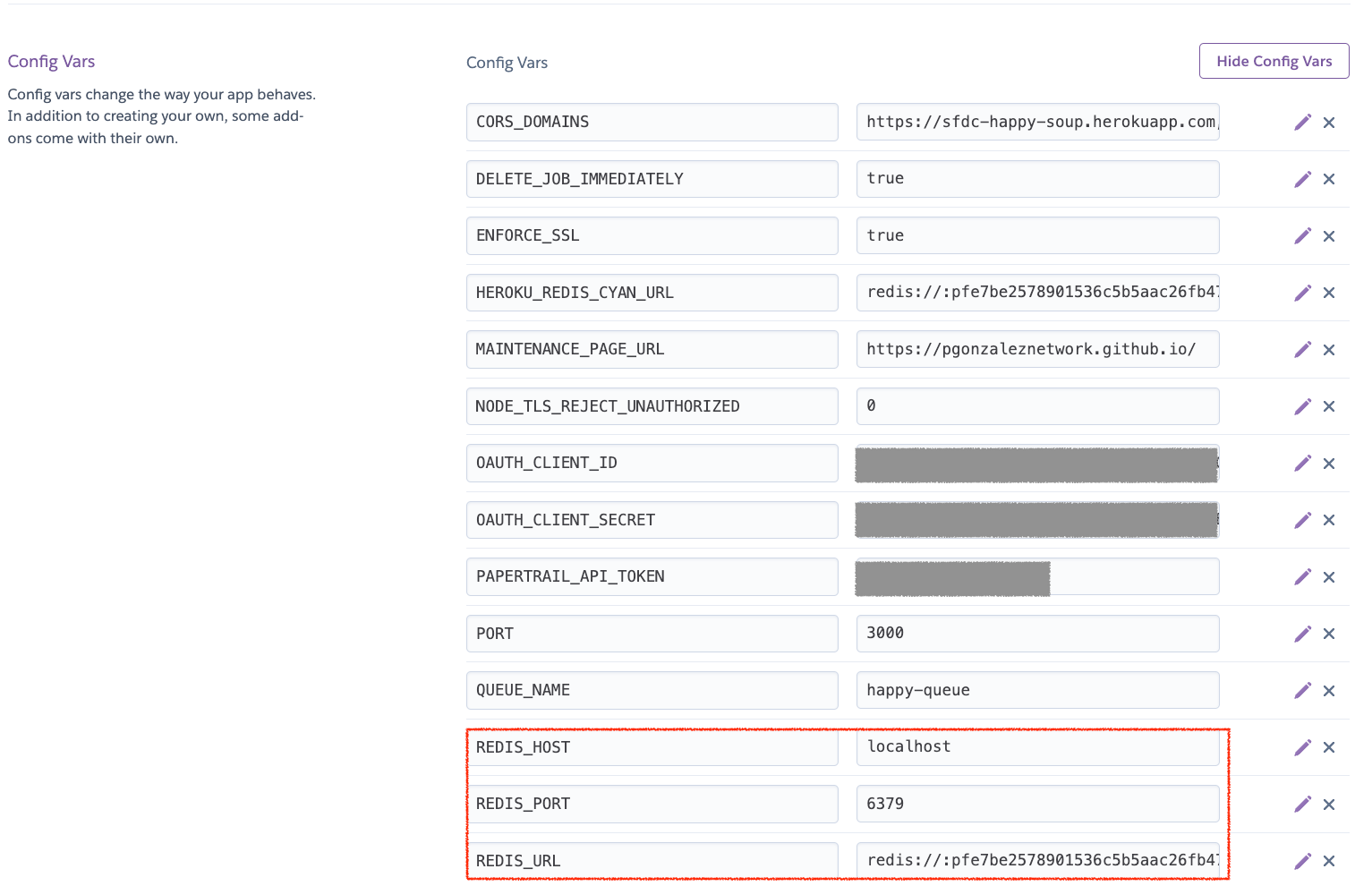
Setting the environment variables
That was a long detour.
The point is that now, we can use environment variables like they are used in traditional software development to automatically deploy org-specific metadata.
So let's see this in action (for real this time):
So back to our sfdx-project.json file, here's what the replacement looks like
"replacements": [
{
"filename": "force-app/main/default/namedCredentials/HappySoup.namedCredential-meta.xml",
"stringToReplace": "https://happysoup.io/auth",
"replaceWithEnv": "HAPPY_SOUP_URL"
}
]Now, I need a way to specify what HAPPY_SOUP_URL resolves to.
If I'm deploying this metadata from VS Code to my dev sandbox, I could add the environment variable just before executing the deploy command, like this
HAPPY_SOUP_URL=https://dev-happysoup.io sfdx force:source:deploy -p force-app
This sets the variable only for this command. And if I open the named credential in my org, it has the new endpoint!
There's a problem with this approach: the environment variable is only "alive" during the execution of the Salesforce CLI command. This means that if I try to deploy the force-app directory again later without specifying the environment variable, it will fail with this error
What we need is a way to specify that the variable should persist throughout the entire session (the session being as long as the terminal is open in VS Code)
We can do this by creating a .env.dev file in the root of our sfdx project. The name of the file doesn't matter; I'm using this terminology to tell the user that this file contains the environment variables for a development sandbox.
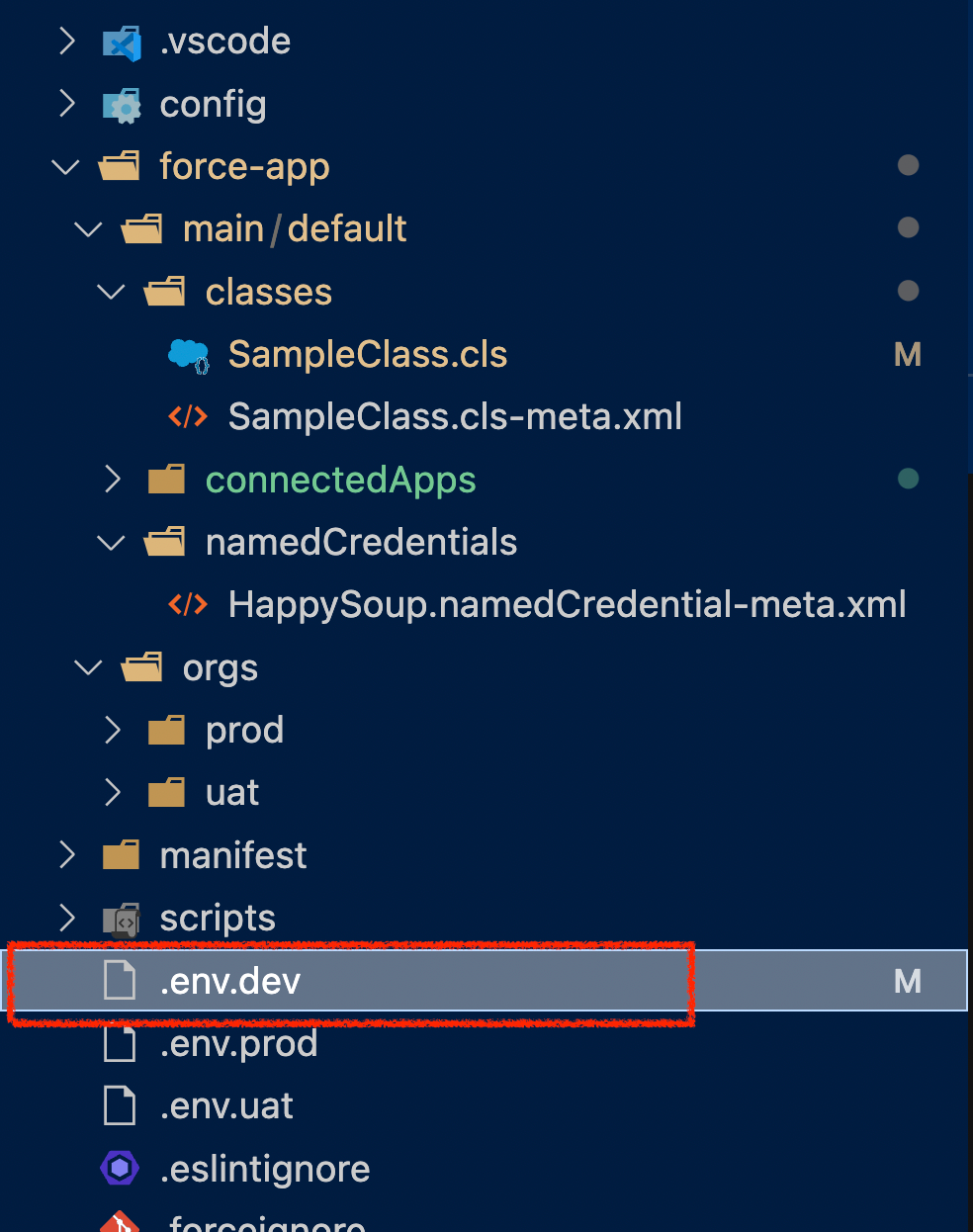
And inside this file, all I need is one line:
export HAPPY_SOUP_URL=https://dev-happysoup.io/auth
Then, we can use the source command (from unix, not sfdx) to execute the file, like this:

The source command basically executes the contents of the .env.dev file. Which in turn, sets the HAPPY_SOUP_URL environment variable. This is basically the same as us manually typing export HAPPY_SOUP_URL=https://dev-happysoup.io/auth in the terminal.
So why are we doing it this way? Because this is a simple example with one environment variable. In the real world, you could have dozens of environment variables.
You don't want your developers to have to write a bunch of export commands every time they copy your sfdx project from GitHub. Instead, all they need to do is source the file and just like that, the variables will be loaded into their current shell session.
Now, I can run sfdx force:source:deploy -p force-app without specifying the environment variable, and I won't get any error. The variable is correctly resolved based on the contents of my .env.dev file.
Using environment variables in CI/CD
Ok, so we know what environment variables are, and how to set them locally when we deploy against our dev sandbox.
How can we set this automatically in a CI server so that when we deploy to UAT, the endpoint is resolved to https://uat-happysoup.io/auth?
First, we can create one env file per Salesforce org, like this:
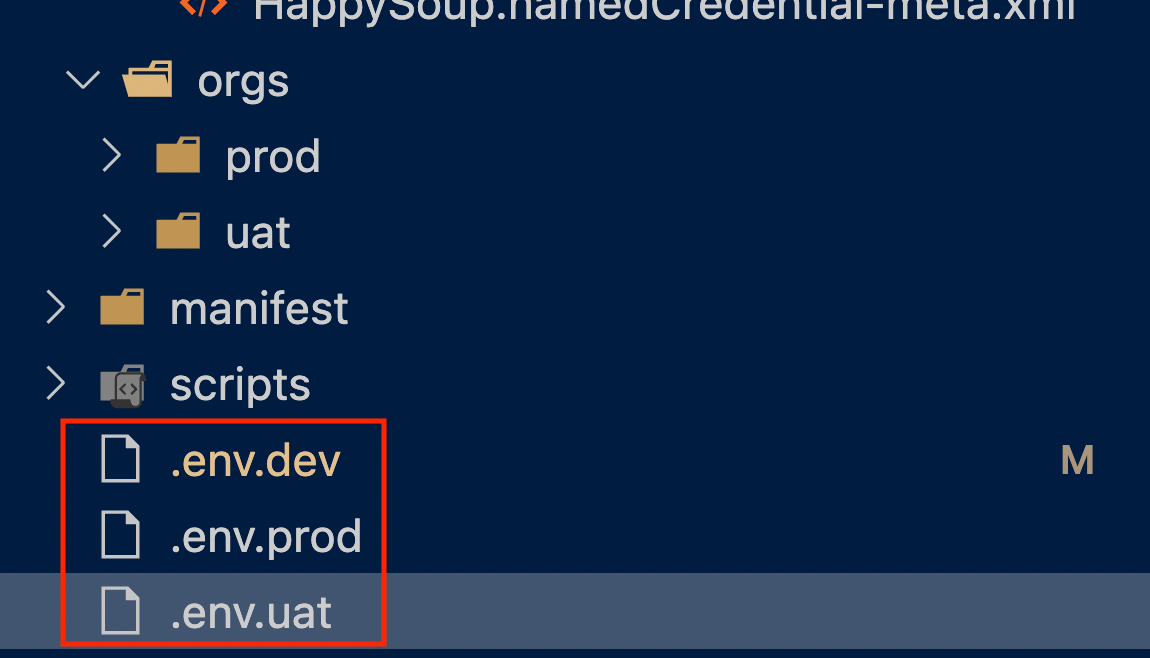
.env.dev file will contain the export command. The other two files, .env.prod and .env.uat will simply have the variable name-value pair, like HAPPY_SOUP_URL=https://uat-happysoup.io/authThis is because in GitHub actions, I cannot use the
source command to load the environment variables. We'll see how we can load them in a bit.Your specific CI server might have a different configuration.
Then, I'm going to edit the XML of the named credential to have a merge field instead of a hardcoded value
<?xml version="1.0" encoding="UTF-8"?>
<NamedCredential xmlns="http://soap.sforce.com/2006/04/metadata">
<allowMergeFieldsInBody>false</allowMergeFieldsInBody>
<allowMergeFieldsInHeader>false</allowMergeFieldsInHeader>
<endpoint>{env.HAPPY_SOUP_URL}</endpoint>
<generateAuthorizationHeader>true</generateAuthorizationHeader>
<label>HappySoup</label>
<principalType>Anonymous</principalType>
<protocol>NoAuthentication</protocol>
</NamedCredential>Notice I changed the endpoint to {env.HAPPY_SOUP_URL}
I'm doing this because I think it's nice to store the metadata this way in version control. It signals to anyone looking at it that this value is org-specific, which is nice! I got this tip from Alba Rivas when she presented this in the Developer Release Readiness video!
That said, the source of the change is always what's configured in the
sfdx-project.json. In other words, simply changing the endpoint to a merge field-like syntax won't do anything unless you have a corresponding configuration in sfdx-project.jsonNow, I need to edit my sfdx-project.json to string replacement object to match the new merge field name
"replacements": [
{
"filename": "force-app/main/default/namedCredentials/HappySoup.namedCredential-meta.xml",
"stringToReplace": "{env.HAPPY_SOUP_URL}",
"replaceWithEnv": "HAPPY_SOUP_URL"
}
]Now, I need to create my GitHub actions workflows.

Both workflows deploy the force-app directory. One workflow fires when a change is made on a uat branch, while the other fires when the change is made against the main branch.
You can see the complete workflows here.
So, how do we load the environment variables? Well, turns out GitHub actions doesn't like it when we use the source command like we did locally earlier.
Instead, I had to use an action from the marketplace that will load the .env file into the GitHub actions context, and then any commands can read those variables.
Here's the action in question. I encourage you to leave a star!
 xom9ikk
xom9ikkAnd here's what the workflow looks like:
- name: Load .env file
uses: xom9ikk/dotenv@v2
with:
path: ./
mode: prod
- name: print env variables
run: echo ${{env.HAPPY_SOUP_URL}}
- name: Deployment
run: sfdx force:source:deploy -p "force-app" --json
shell: bashThe mode property of the xom9ikk/dotenv@v2 action is the suffix of the .env file that I want to load. Because I want to load the .env.prod file, I specified the value prod.
Then, I can simply run the sfdx force:source:deploy command and it "knows" how to resolve the HAPPY_SOUP_URL environment variable.
The command also prints any replacements that took place at deployment time:
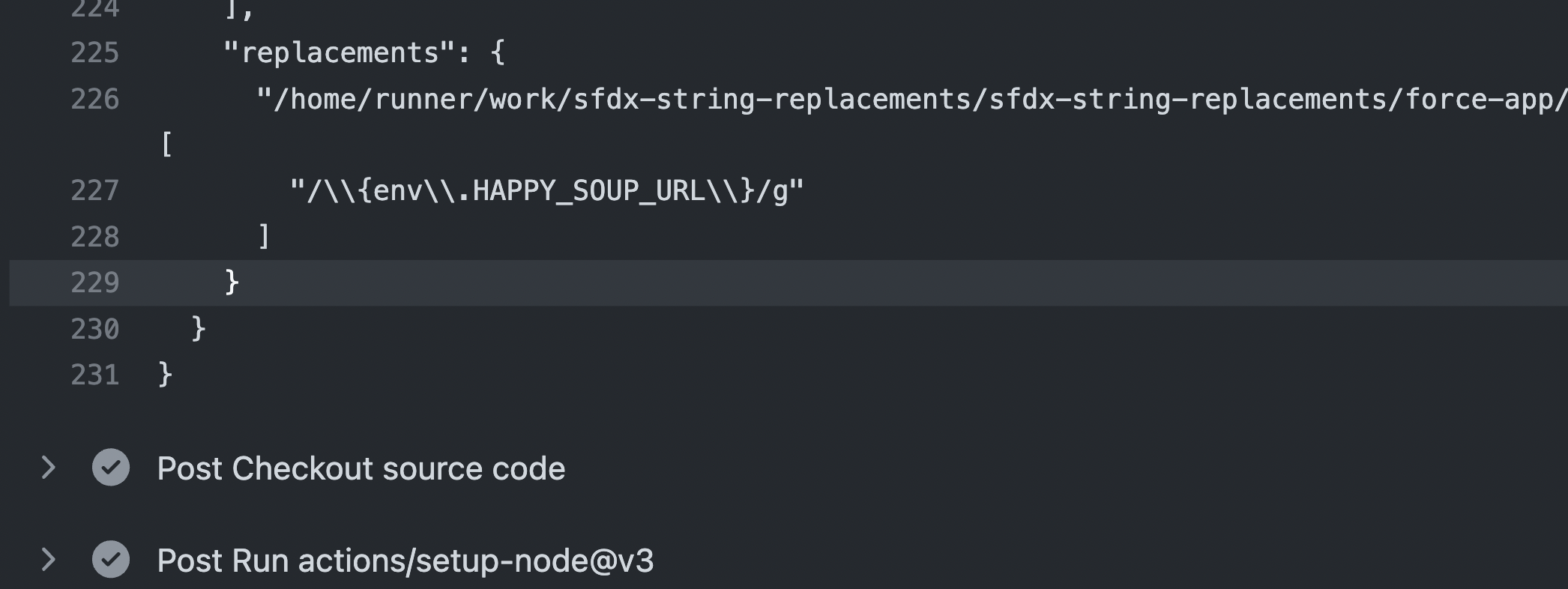
And that's it!
Final thoughts and recommendations
I really love this feature, and I'm so happy I got it to work as expected (it took a while!)
I have a few departing thoughts:
1- You may be using a different CI server; if that's the case, I'm sorry this demo doesn't apply to you. But the concept is the same; just look at the documentation of your CI server and see how to load a env file into the execution context.
2- Read the below callout twice!
.env file. In the example above, the string to be replaced was a simple URL.If you are replacing some authentication information, store those variables as secrets in your CI server, don't commit them to version control.
3- There are a few other things you can do with string replacements, such as conditionally changing a string depending on the value of another environment variable.
You can also use regex to match the string to be replaced.
The documentation has a lot of tips and you should definitely pay a visit:
 Salesforce
SalesforceHappy deploying!