CPQ Data Deployments—How Salto did the impossible
For those of you who don’t know, I work at Salto.io, and we recently introduced some awesome changes that improve our DevOps offering for CPQ configuration data.
Since this blog is all about CI/CD and DevOps, I thought it would be fitting to talk about this new approach, as it is quite novel for the Salesforce ecosystem.
So let me start by explaining what’s the problem with CPQ data and why DevOps practices can solve these problems (and how we did it).
If you just want to see it in action, you can watch this video:
Data that wants to be metadata
There are two types of data in Salesforce:
Standard data: These are data records such as Accounts, Leads, and Cases representing entities your company deals with.
Configuration Data: This is data in your Salesforce org that controls the run-time behavior of certain business processes.
Examples of configuration data can be found all over Salesforce CPQ, for example:
- Product Rules
- Option Constraints
- Price Rules
- Error Conditions
The way these records are configured affects how your CPQ logic works. In fact, CPQ is configured by creating and editing these data records.
If Salesforce CPQ was a standard Salesforce feature, perhaps many of these rules could be configured via the Setup menu. But because it's a managed package, all the configuration has to be done with data records instead of metadata.
Why that sucks
Configuration data cannot be deployed with change sets or via the metadata API. There's no easy way to deploy it across environments while maintaining relationships. There's no standard process to roll back to a previous version or to see the history of this data over time.
Essentially, Salesforce CPQ data is like metadata but without all the benefits of the Metadata API.
An infrastructure-as-code approach
In Salto, we fix this problem by treating CPQ configuration data as metadata. We do this by translating CPQ data to NaCl, our own infrastructure-as-code language that we use to describe the configuration of any business application.
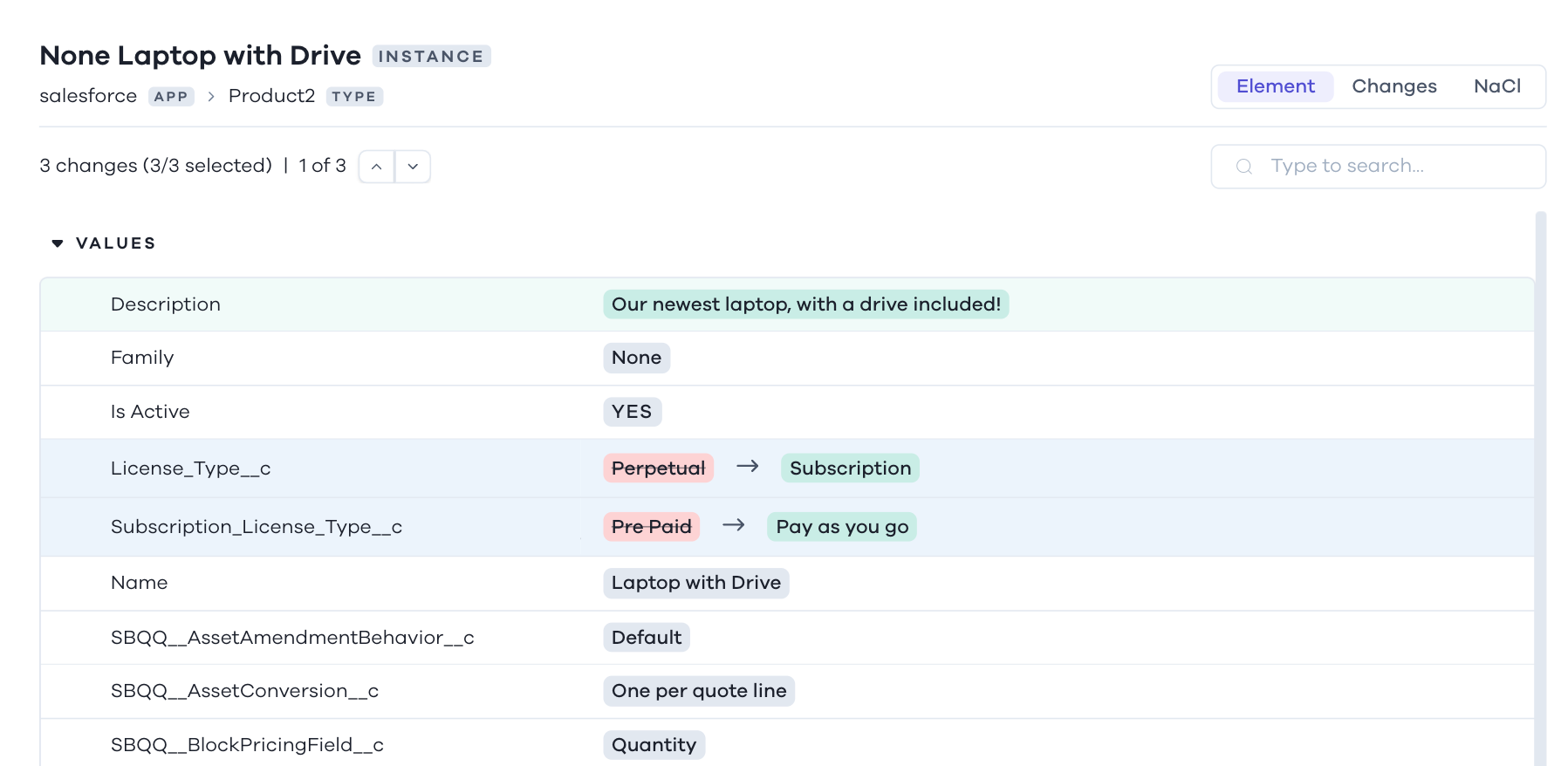
Let’s see what a Produc2 record looks like:
salesforce.Product2 "01t3H000003FaRjQAK" {
Family = "None"
IsActive = true
License_Type__c = "Subscription"
Name = "Laptop with Drive"
SBQQ__AssetAmendmentBehavior__c = "Default"
SBQQ__AssetConversion__c = "One per quote line"
SBQQ__BlockPricingField__c = "Quantity"
SBQQ__Component__c = false
SBQQ__CostEditable__c = false
SBQQ__CustomConfigurationRequired__c = false
SBQQ__DefaultQuantity__c = 1
SBQQ__DescriptionLocked__c = false
SBQQ__EnableLargeConfiguration__c = false
SBQQ__ExcludeFromMaintenance__c = false
SBQQ__SubscriptionBase__c = "List"
SBQQ__SubscriptionType__c = "Renewable"
SBQQ__Taxable__c = false
Subscription_License_Type__c = "Pay as you go"
_alias = "None Laptop with Drive"
Description = "Our newest laptop, with a drive included!"
}
We can also look at a SBQQ__ProductFeature__c record that uses that product
salesforce.SBQQ__ProductFeature__c a0p3H000000oyS1QAI {
SBQQ__ConfiguredSKU__c = salesforce.Product2.instance.01t3H000003FaRjQAK
SBQQ__MinOptionCount__c = 1
SBQQ__Number__c = 1
Name = "E-Port"
_alias = "None Laptop with Drive E-Port"
}
You’ll see that the 2nd line has a direct reference to that product.
This makes this language superior to JSON or XML because it understands dependencies, relationships, types, and other constraints.
Specific DevOps Practices
Let’s look at some specific DevOps practices that this approach enables
Deployments
We can deploy CPQ data from one org to another using the same mechanism we use to deploy metadata. Everything that we can do with metadata is available, for example:
Org comparison
We can compare 2 orgs and see their differences in terms of their CPQ data. In this screenshot, I can see all the CPQ records that exist in Production and A) don’t exist in my sandbox or B) are different in my sandbox
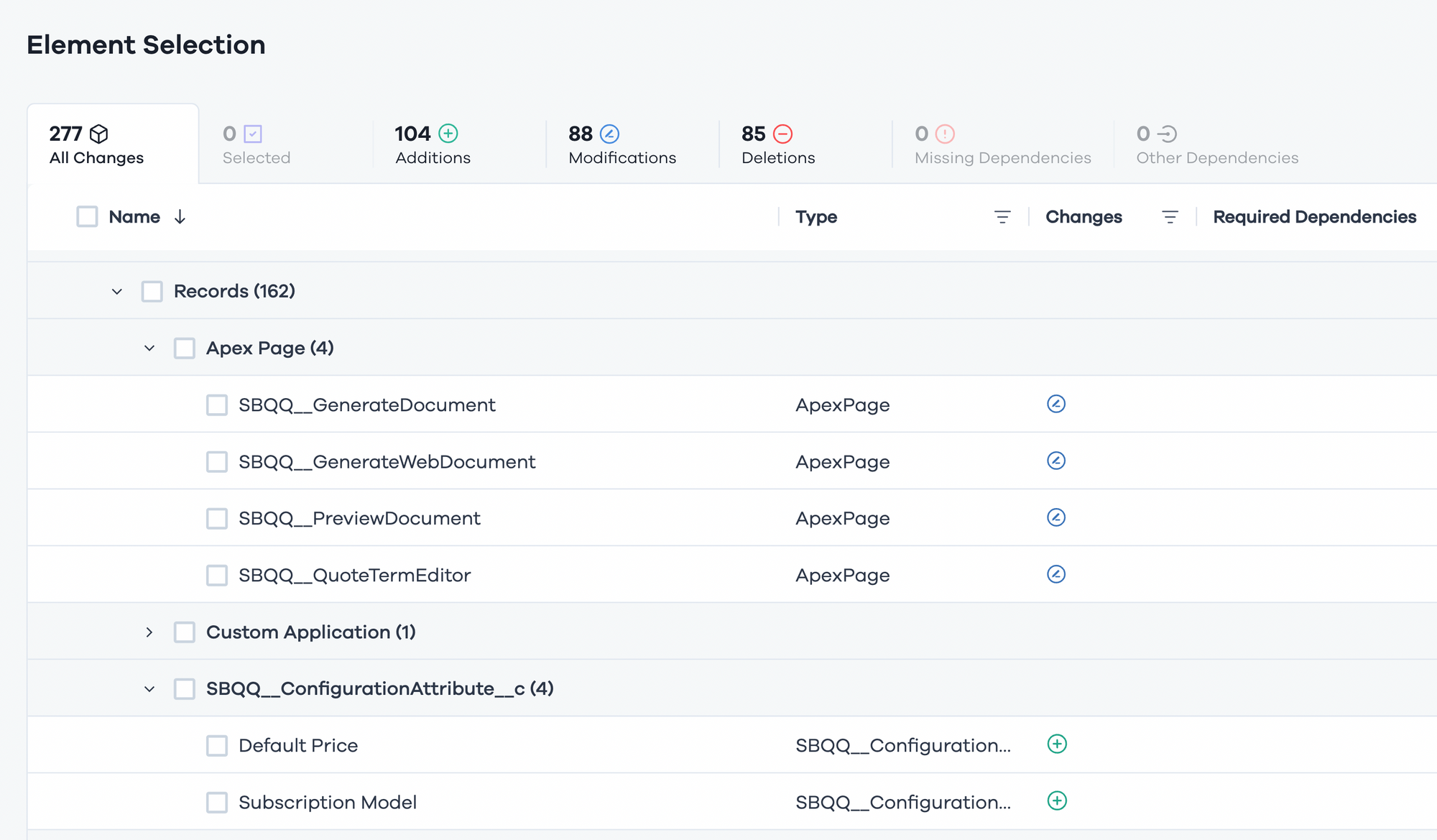
If a record exists in both environments, I can also see the differences
Also, notice how this is a nice-looking UI, not some ugly XML 🙂
Success at first deployment
Once I know what’s different, I can choose which records to deploy, and Salto will show me if there are any required dependencies in order to deploy this data
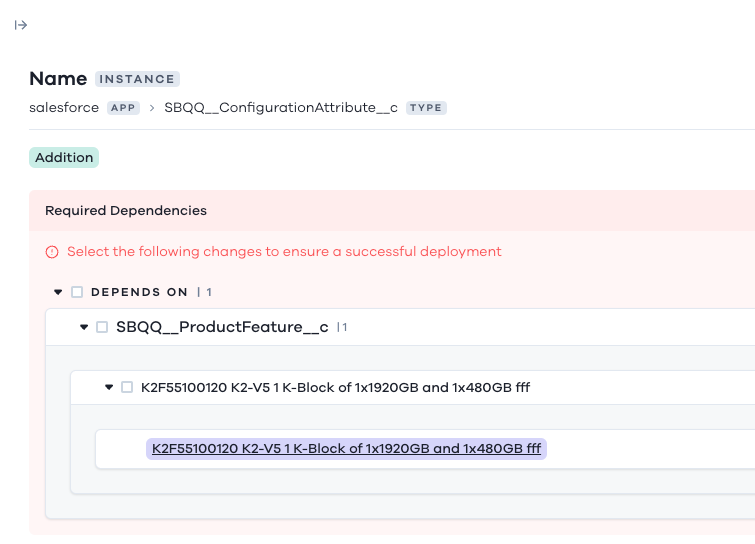
For example, before I can deploy this configuration attribute, I need to include a related product feature.
Version control with Git
Obviously, version control is at the heart of CI/CD. It’s great that we can deploy CPQ data but being able to store it in version control is the real game changer.
For example, I can see here all the commits that have edited this specific Product2 record
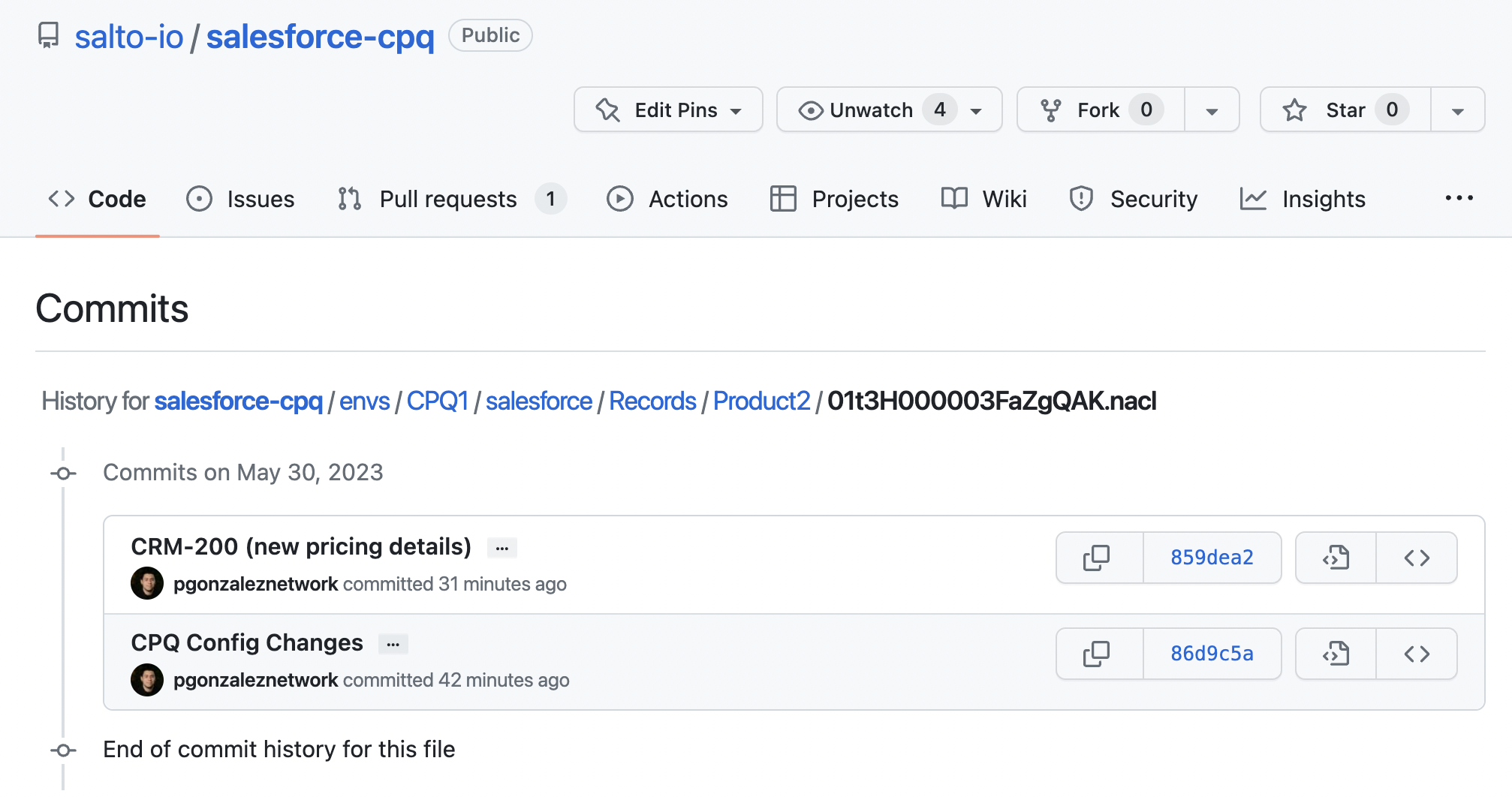
And if I drill down to a specific commit, I can see what changed, by whom, why, and what environment the change came from
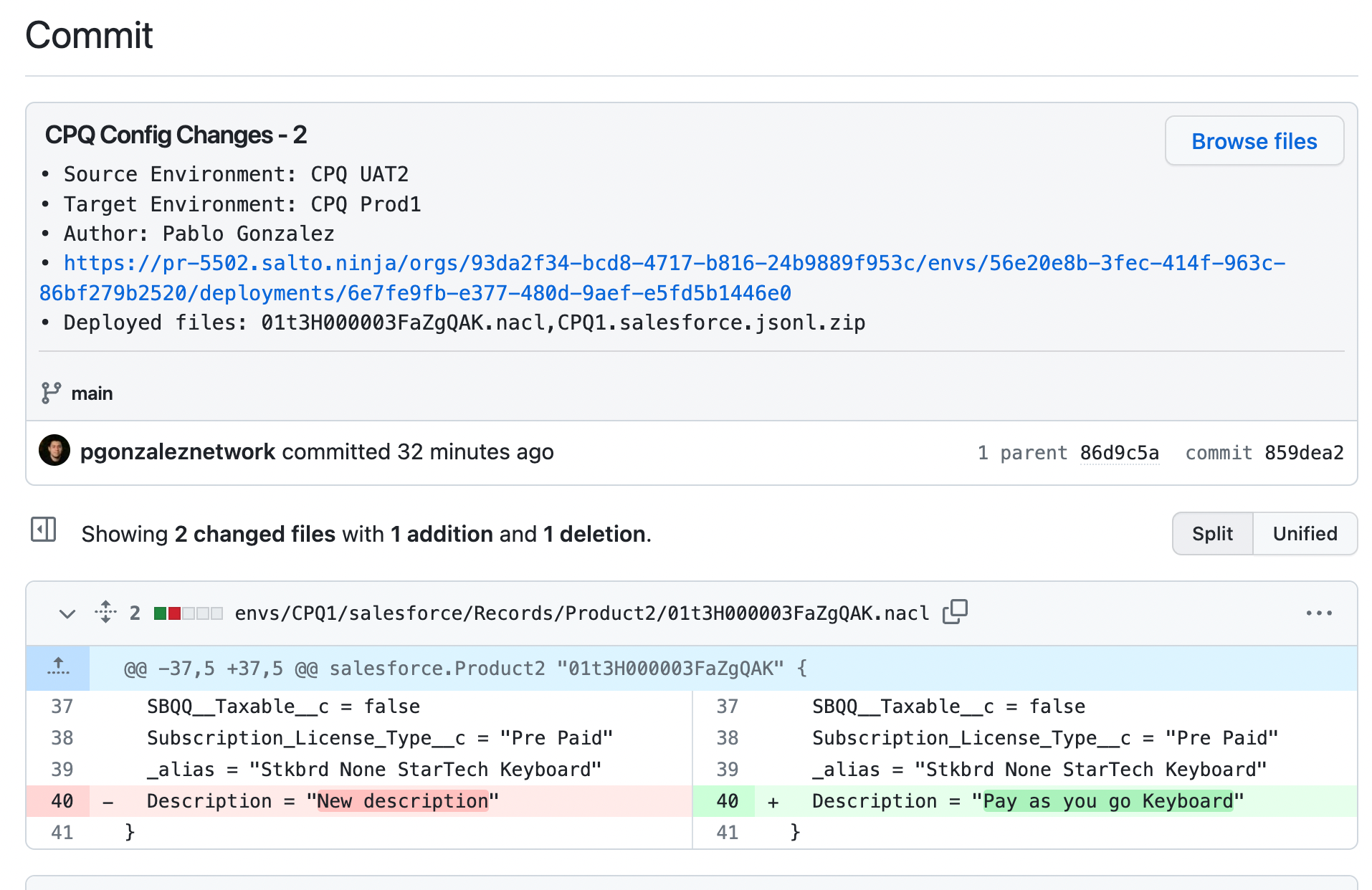
This is infinitely more powerful than simple field history tracking.
Collaboration via pull requests
Of course, another benefit of having our CPQ data in Git is we can use pull requests for collaboration and automation.
Salto automatically creates a pull request when I start a deployment.
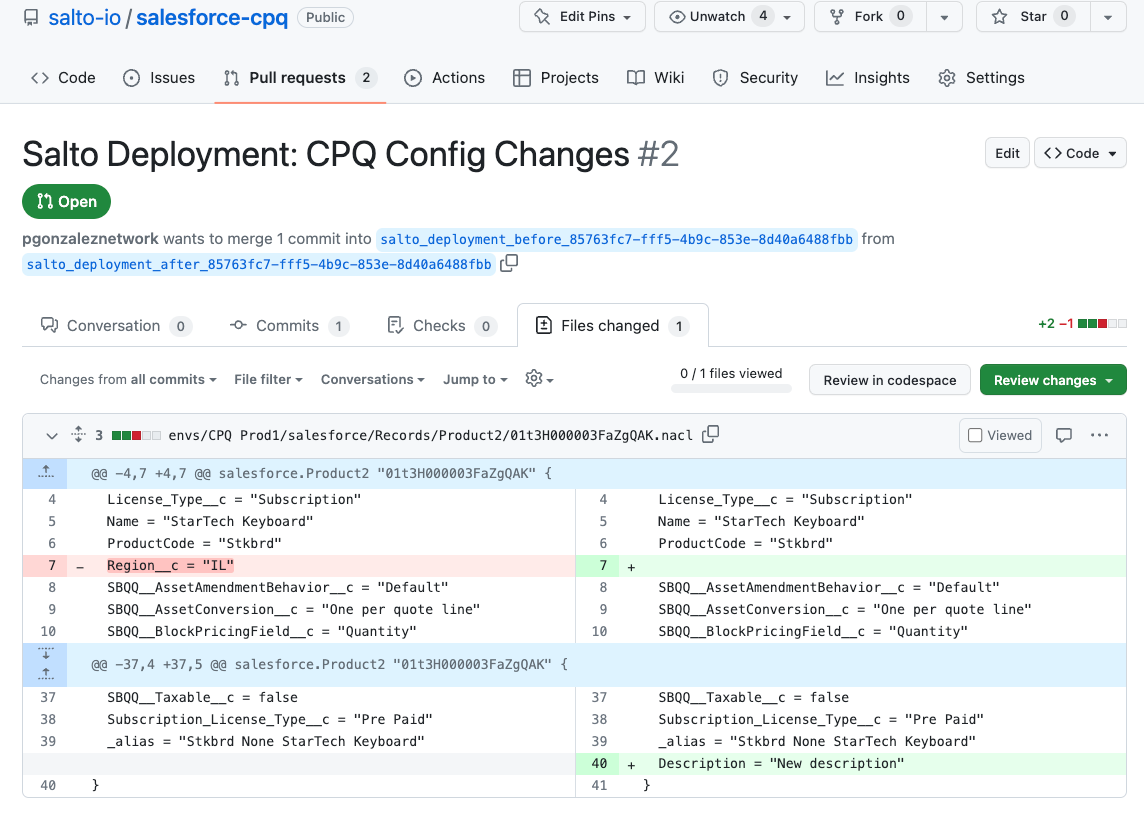
I can then use this to enable a more senior member of my team or perhaps a product owner, to review the CPQ changes.
Continuous Integration
Now, this is the bit that is challenging. If you’ve read my article on continuous integration, you know it’s all about answering 2 questions
1- Are your changes deployable?
2- Do they break anything, and do they still work as expected?
Clearly, with CPQ data, this is not straightforward, as it’s not possible to do a validation deployment that would be rolled back if there were any failures. Also, for the most part, developers don’t write tests that validate the behavior of their CPQ configuration.
What we do have, are deployment preview errors. These are validators that, well, validate the semantics of the NaCl files you are trying to deploy. A specific example is we can tell you if you are trying to deploy a record that contains a non-existing picklist value

Note this error is shown before you even deploy the data, and we have many others. This helps make sure your CPQ changes are deployable, which is one of the core principles of continuous integration.
Can I try it?
Yes, you can start a 30-day free trial here. The trial includes deployments and everything I’ve shown here.
After the trial expires, you’ll revert back to the free tier, which allows you to map all dependencies across your CPQ data and find where it is being used, which is still a super awesome use case!